

How To Find Standard Deviation Of Ungrouped Data
Standard departure Role in Python pandas (Dataframe, Row and column wise standard divergence)
Standard deviation Role in python pandas is used to calculate standard deviation of a given set of numbers, Standard deviation of a information frame, Standard deviation of column or cavalcade wise standard deviation in pandas and Standard departure of rows, allow'south see an instance of each. We need to utilize the package proper noun "statistics" in calculation of median. In this tutorial we volition learn,
- How to find the standard difference of a given set of numbers
- How to detect standard deviation of a dataframe in pandas
- How to observe the standard difference of a cavalcade in pandas dataframe
- How to detect row wise standard deviation of a pandas dataframe
Syntax of standard deviation Function in python
DataFrame.std(axis=None, skipna=None, level=None, ddof=1, numeric_only=None)
Parameters :
axis : {rows (0), columns (i)}
skipna : Exclude NA/nothing values when computing the result
level : If the centrality is a MultiIndex (hierarchical), count forth a detail level, collapsing into a Series
ddof :Delta Degrees of Freedom. The divisor used in calculations is Northward – ddof, where Due north represents the number of elements.
numeric_only : Include only bladder, int, boolean columns. If None, will endeavour to use everything, then use only numeric data. Not implemented for Serial.
Standard deviation Office in Python pandas
Simple standard deviation function is shown below
# summate standard departure import numpy as np print(np.std([one,9,five,vi,8,seven])) print(np.std([four,-11,-5,16,five,seven,9]))
output:
2.82842712475
8.97881103594
Standard deviation of a dataframe in pandas python:
Create dataframe
import pandas as pd import numpy as np #Create a DataFrame d = { 'Name':['Alisa','Bobby','Cathrine','Madonna','Rocky','Sebastian','Jaqluine', 'Rahul','David','Andrew','Ajay','Teresa'], 'Score1':[62,47,55,74,31,77,85,63,42,32,71,57], 'Score2':[89,87,67,55,47,72,76,79,44,92,99,69], 'Score3':[56,86,77,45,73,62,74,89,71,67,97,68]} df = pd.DataFrame(d) df So the resultant dataframe will be
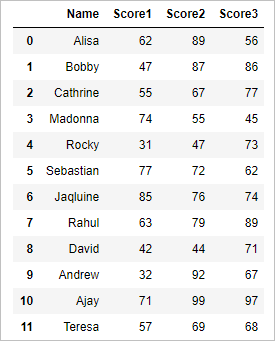
Standard difference of the dataframe in pandas python:
# standard departure of the dataframe df.std()
will calculate the standard departure of the dataframe across columns then the output volition
Score1 17.446021
Score2 17.653225
Score3 xiv.355603
dtype: float64
Column wise Standard deviation of the dataframe in pandas python:
# column standard deviation of the dataframe df.std(axis=0)
axis=0 argument calculates the column wise standard deviation of the dataframe then the effect will be
Score1 17.446021
Score2 17.653225
Score3 fourteen.355603
dtype: float64
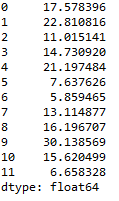
Row standard divergence of the dataframe in pandas python:
# Row standard difference of the dataframe df.std(centrality=one)
axis=1 argument calculates the row wise standard deviation of the dataframe so the consequence will be
Calculate the standard deviation of the specific Column in pandas python
# standard deviation of the specific column df.loc[:,"Score1"].std()
The in a higher place lawmaking calculates the standard departure of the "Score1" column so the upshot will be
17.446020645512156
![]()
![]()

Source: https://www.datasciencemadesimple.com/standard-deviation-function-python-pandas-row-column/
Posted by: gillespieextesed.blogspot.com
0 Response to "How To Find Standard Deviation Of Ungrouped Data"
Post a Comment